세그먼트(인덱스)트리
주어진 데이터의 구간 합(합배열)과 데이터 업데이트를 빠르게 수행하기 위해 고안해 낸 자료구조의 형태
더 큰 범위로 '인덱스 트리' 라고 불리며 이는 코딩테스트 영역에서 큰 차이가 없음.
구간합이 있는데 왜 세그먼트 트리를 학습하여 사용하는가?
합배열의 가장 큰 문제점은 특정 데이터 업데이트시 굉장히 느리다.
만약 1번 인덱스 값 5를 10으로 변경한다면 나머지 모든 구간에 5를 더해줘야 한다.
| 인덱스 | 0 | 1 | 2 | 3 | 4 | 5 | 6 |
| 데이터 | 3 | 5 | 4 | 2 | 3 | 7 | 4 |
| 합배열 S | 3 | 8 | 12 | 14 | 17 | 24 | 28 |
index 4의 구간합인 17은 index 0 ~ 4까지의 데이터의 합이다.
합배열로는 S[4]로 표현하며 S[4] = S[3] + A[4] 라는 공식이 성립된다.
중간 영역인 index 2 ~ 5 까지의 합은 index 0 ~ 5 까지 합 - index 0 ~ 1 까지의 합이다.
이는 S[5] - S[1] 라는 구간합 공식이 성립된다.
만약 구간합을 모두 구한 뒤 1번 인덱스의 값 5를 10으로 변경한다면
해당 인덱스 이후의 모든 구간에 대한 합배열값에 5를 더해줘야 한다.
즉, 구간합을 구하려 할 때 데이터의 업데이트가 빈번하게 일어나게 되면 합배열이 성능측면에서 굉장히 안좋아 진다.
세그먼트 트리는 이러한 구간합을 빠르게 구할 수 있으면서도, 데이터가 빈번하게 일어날 때도 속력을 유지할 수 있는 자료구조 형태이다.
핵심이론
| 종류 | 구현 단계 |
| 구간 합, 구간 곱, 구간 최댓값, 구간 최솟값 | ①트리 초기화 하기, ②질의 값 구하기, ③ 데이터 업데이트 하기 |
세그먼트 트리 과정
- 트리초기화하기
- 질의값구하기
- 데이터 업데이트
Step 01) 트리 초기화 하기
기본적으로 세그먼트 트리는 이진트리로 이루어 져 있으며, 리프 노드는 원본 데이터 배열이고 그 윗 부분은 각 조건에 맞게 업데이트 한 후 채워넣는다. (끝 부터 데이터를 채워 넣기 위해서)
1. 트리의 갯수를 구한다.
index트리를 1차원 배열로 나타내야 하며, 끝부터 데이터를 채워넣기 위해 배열의 크기를 알아야 한다.
트리 배열의 크기를 구하는 방법은 2ᵏ ≥ n을 만족하는 k의 최솟값을 구한 후 2ᵏ * 2 즉, 2ᵏ⁺¹ 를 트리배열의 크기로 정의한다.
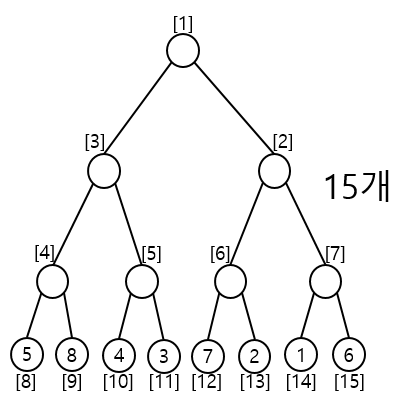
ex) {5, 8, 4, 3, 7, 2, 1, 6}
n = 8 이고 이는 2³ ≥ 8 을 만족하므로 배열 크기는 2³ * 2 즉, 2⁴인 16으로 정의한다.
데이터가 5개 6개 7개여도 16인 이유
예를들어 리프노드에 5개의 노드가 있다면 이는 2² ≥ 5를 만족하지 않고 2³ ≥ 5 를 만족한다.
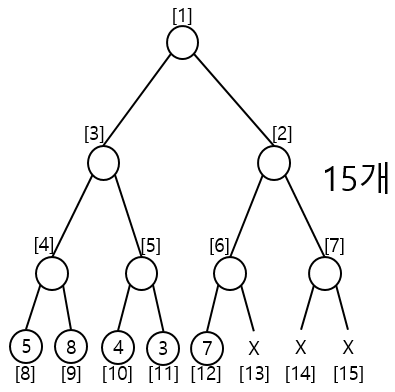
우측과 같이 트리의 표현에서 리프노드에서는 노드로서 존재하지 않지만 트리의 구조상 해당 값들도 배열로 표현해야 하고 이를 배열로 표현하기 위해서는 배열의 크기는 빈값도 포함하는 갯수로 정의해야 한다.
2. 리프노드 인덱스 도출 및 트리 배열 초기화
주어진 예제의 원본 데이터는 트리상 리프노드에 넣어야 하므로 리프노드의 시작위치를 구해야 한다.
이때 2ᵏ를 시작 인덱스로 취하고 이렇게 구해진 리프노드의 시작 위치를 트리배열의 인덱스로 적용하여 각 노드의 값을 트리배열상 해당하는 인덱스 위치에 저장한다.
시작 노드 k가 3이라면 start index는 8이 된다.
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| X | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 5 | 8 | 4 | 3 | 7 | 2 | 1 | 6 |
위의 배열을 표현한 표와 같이 8번째 인덱스부터 차례대로 각 리프노드에 저장된 데이터를 배열인덱스의 위치에 맞게 차례대로 저장한다.
index 1 ~ 7에는 리프노드를 제외한 각 리프노드의 부모노드들을 2ᵏ - 1번 인덱스부터 1번 인덱스 쪽으로 순차저장한다.
채워 나가야 하는 인덱스가 N이라고 가정하면 자신의 자식노드를 이용해 해당 값을 채울 수 있다.
자식 노드의 인덱스는 이진 트리 형태에서 자신(부모) N * 2 혹은 N * 2 + 1이 된다.
(역으로 부모 인덱스는 자신(자식) N / 2)
구간합 A[N] = A[2N] + A[2N+1] (N= 2ᵏ - 1 부터 -1씩 감소)
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| X | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 5 | 8 | 4 | 3 | 7 | 2 | 1 | 6 |
부모 노드는 각 인덱스 / 2 이다
index 15에 해당하는 노드의 부모 노드는 15/2 인 index 7번 노드에 해당한다.
따라서 index 15번 노드의 값 6을 부모노드인 index 7위치에 저장한다.
최초 저장시 구현된 코드상으로 트리배열의 초기값이 0으로 초기화된 상태에 합하는것으로 구현한다.
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| X | 0 | 0 | 0 | 0 | 0 | 0 | 0 + 6 | 5 | 8 | 4 | 3 | 7 | 2 | 1 | 6 |
index 14에 해당하는 노드의 부모 노드는 14/2 인 index 7번 노드에 해당한다.
따라서 index 14번 노드의 값 1을 부모노드인 index 7위치에 저장한다.
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| X | 0 | 0 | 0 | 0 | 0 | 0 | 6 + 1 | 5 | 8 | 4 | 3 | 7 | 2 | 1 | 6 |
이전에 초기값 0에 6을 더했으므로 이번엔 6에 1을 더한다.
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| X | 0 | 0 | 0 | 0 | 0 | 0 | 7 | 5 | 8 | 4 | 3 | 7 | 2 | 1 | 6 |
이를 공식으로 대입하면 A[7] = A[14] + A[15]가 되고
이와같이 배열 부모노드 인덱스 뒤에서부터 탐색(2ᵏ - 1 부터 -1씩 감소) 하며 각 점화식에 대입한다.
| 부모 인덱스 |
1 |
2 |
3 |
4 |
5 |
6 | 7 | ||||||||
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| X | 36 | 20 | 16 | 13 | 7 | 9 | 7 | 5 | 8 | 4 | 3 | 7 | 2 | 1 | 6 |
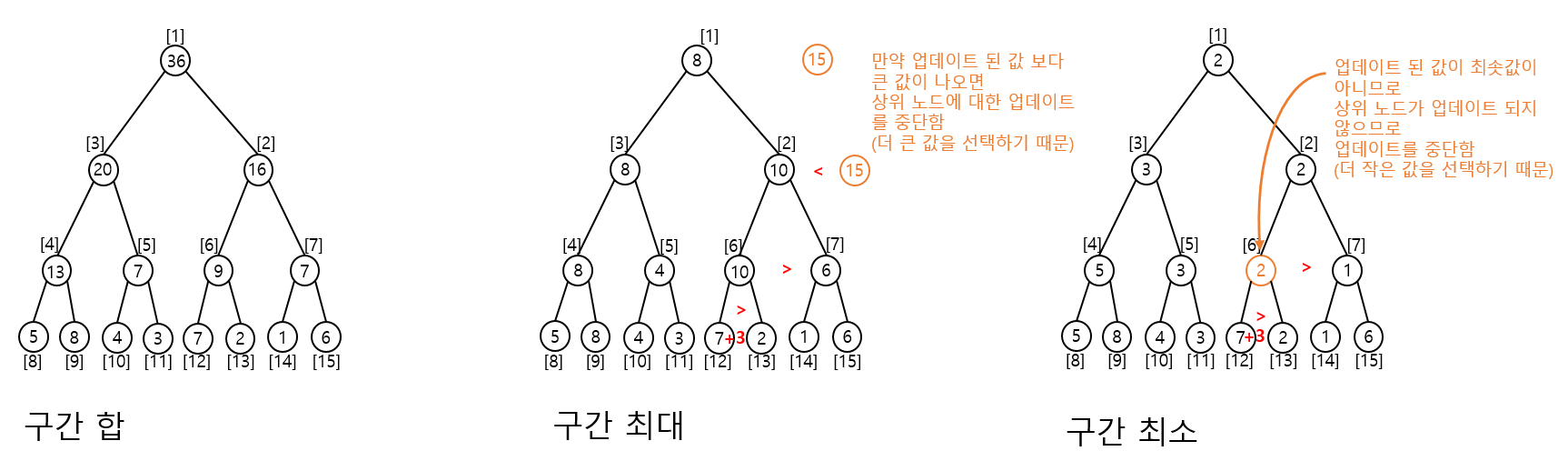
최댓값 A[N] = max(A[2N], A[2N+1] )
| 부모 인덱스 |
1 |
2 |
3 |
4 |
5 |
6 | 7 | ||||||||
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| X | 8 | 8 | 7 | 8 | 4 | 7 | 6 | 5 | 8 | 4 | 3 | 7 | 2 | 1 | 6 |
최솟값 A[N] = max(A[2N], A[2N+1] )
| 부모 인덱스 |
1 |
2 |
3 |
4 |
5 |
6 | 7 | ||||||||
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| X | 1 | 3 | 1 | 5 | 3 | 2 | 1 | 5 | 8 | 4 | 3 | 7 | 2 | 1 | 6 |
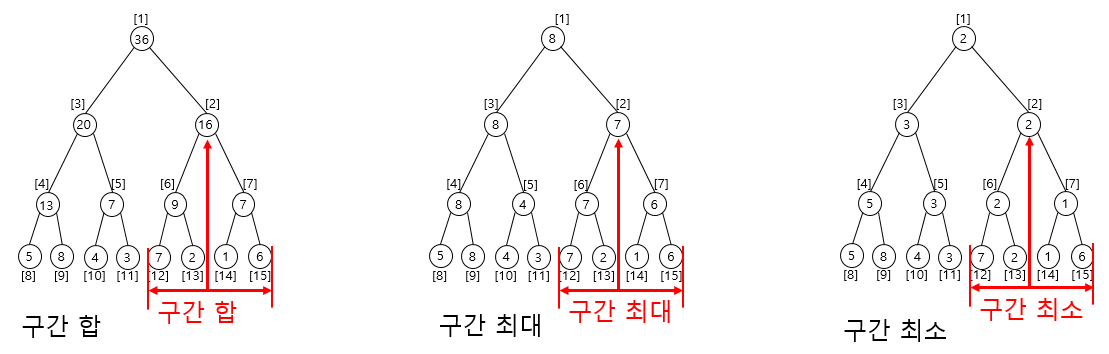
Step 02) 질의 값 구하기
주어진 질의 인덱스를 세그먼트 트리의 리프 노드에 해당하는 인덱스로 변경한다.
기존 샘플을 기준으로 한 인덱스 값과 세그먼트 트리 배열에서의 인덱스 값이 다르기 때문에 변경해야 한다.
변경 공식
리프노드index = 질의index + 2ᵏ -1
ex) k = 3 이고 질의 범위를 1 ~ 4라고 가정했을 때의 리프노드index
1+2³-1 = 8
4+2³-1 = 11
변경된 리프노드 인덱스 범위 8~11
질의값 구하는 과정
① start_index % 2 == 1 해당 노드 선택
(start 기준 0이면 부모노드 범위 내에서 완전히 포함된 왼쪽 노드 이므로 선택할 필요가 없다.)
② end_index % 2 == 0 해당 노드 선택
(end 기준 1이면 부모노드 범위 내에서 완전히 포함된 오른쪽 노드 이므로 선택할 필요가 없다.)
③ start_index Depth 변경 : start_index = (start_index+1) / 2
(독립노드로 선택되어 격리된 상황까지 고려한 계산법)
④ end_index Depth 변경 : end_index = (end_index-1) / 2
(독립노드로 선택되어 격리된 상황까지 고려한 계산법)
⑤ ①~ ④를 반복하며 end_index < start_index 조건을 만족할 경우에 종료한다.
(기본적으로 start_index가 end_index보다 작으므로 위치가 바뀌었다고 이해)
①~② 과정에서 해당 노드 선택의 의미
- 해당 노드의 부모가 나타내는 범위가 질의 범위를 넘어가기 때문에 해당 노드를 질의값에 영향을 미치는 독립노드로 선택
(이는 노드의 부모노드는 대상 범위에서 제외한다는 의미)
③~④ 과정에서 공식의 +1과 -1의 의미
- 독립노드로 선택된 노드의 부모노드를 대상범위에서 제거하여 depth를 변경하는 공식
(기본적으로 트리에서 부모노드로 이동하기 위해 index/2를 하는데 질의 범위에 해당하는 위의 독립노드 예외 경우까지 고려하여 +1, -1을 적용하여 /2 수행)
질의에 해당하는 노드 선택 방법은 구간합, 구간곱, 구간최댓값, 구간최솟값 모두 동일하며 선택된 노드들에 관해 마지막 연산식만 다르다.
| 구간합 | 선택된 노드 모두 더한다. |
| 구간 최대/최소 | 선택된 노드 중 (max/min)값 선택 후 출력한다. |
ex) 질의범위 2~6 구간 합 예제
1) 리프노드의 인덱스로 변경

- start_index = 2 + 8 - 1 = 9
- end_index = 6 + 8 - 1 = 13
- 범위 : 9 ~ 13
2) 부모노드로 이동
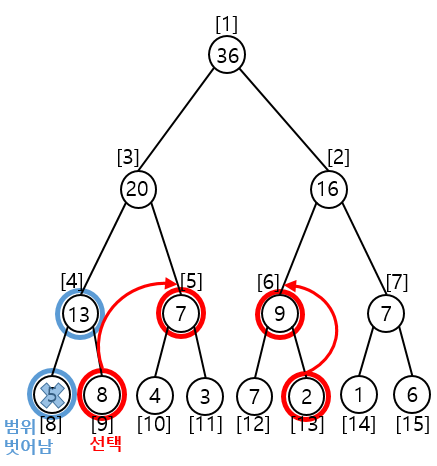
① 독립노드 선택
시작노드 : [start_index % 2 == 1] 9 % 2 == 1 노드 선택
끝노드 : [end_index % 2 == 0] 13 % 2 == 1 노드 미선택
③ 부모노드로 Depth 변경
시작노드 : (start_index+1) / 2 = (9 + 1)/2 = 5
끝노드 : (end_index+1) / 2 = (13-1)/2 = 6
3) 한번 더 부모노드로 이동
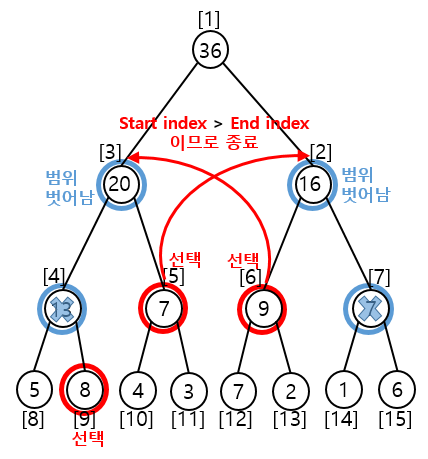
① 독립노드 선택
시작노드 : [start_index % 2 == 1] 5 % 2 == 1 노드 선택
끝노드 : [end_index % 2 == 0] 6 % 2 == 0 노드 선택
③ 부모노드로 Depth 변경
시작노드 : (start_index+1) / 2 = (5 + 1)/2 = 3
끝노드 : (end_index+1) / 2 = (6-1)/2 = 2
누적으로 선택된 index에 해당하는 노드 총합이 곧 구간합이 된다.
A[9] + A[5] + A[6] = 8 + 7 + 9 = 24
부모노드 탐색시 start+1 혹은 end-1 하는 이유
그래프
인덱스 9에 해당하는 노드 8의 부모노드인 index4의 노드13은
9~13 범위 이외의 index8의 노드 5도 가지고 있게 된다.
start 노드 선택 기준에서 1이 나왔다는 것은 오른쪽 노드라는 의미이고
이때 리프 index의 범위에서 벗어난 노드의 부모노드를 사용하지 않으므로
추후 인덱스 9에 해당하는 start노드를 구간합 연산시 사용해야 하므로 독립노드로 따로 keep한다.
앞서 부모노드를 사용하지 않기 때문에 해당 부모노드인 index4의 다음노드인 index9로 점프한다.
(이때 start_index + 1을 하는 이유는 /2로 부모 탐색시 범위에 포함되는 노드라면 정상적으로 계산되지만 범위가 아니라면 우측(2N+1)이므로 +1 하여 다음노드로 넘어가는것을 고려하는 연산임)
Step 03) 데이터 업데이트 하기
왜 빠를까?
트리의 노드 갯수가 n = 10000개에서 10000개 중 2번째 데이터가 변경되었다고 가정해본다
- prefix sum : 2~10000까지 모두 들리면서 update한다.
- segment tree : 2ᵏ ≥ 10000 을 만족하는 k = 13이 되므로 13번 update한다.
업데이트 방식은 자신의 부모노드로 이동하면서 업데이트한다는 것은 동일하지만, 어떤 값으로 업데이트 할 것인지에 관해서는 트리 타입별로 조금 다르다.
기존 이진트리처럼 index/2로 부모를 찾아가면서 업데이트 한다.
구간 합에서는 원래 데이터와 변경 데이터의 차이 만큼 부모노드로 올라가면서 변경한다.
최대/최소값 찾기 에서는 변경데이터와 자신과 같은 부모를 지니고 있는 다른 자식노드를 비교해 더 큰(작은) 값으로 업데이트 한다.
두 경우 만약 업데이트가 발생하지 않으면 종료한다.
세그먼트 트리 단계 정리
① 트리 초기화 하기
- 크기 정하기
2ᵏ ≥ n을 만족하는 k를 찾은 후 2ᵏ * 2 즉, 2ᵏ⁺¹ 만큼의길이의 배열을 생성한다. - 부모노드 값 채우기
- 2ᵏ 만큼 start_index를 구하여 리프데이터를 초기화 한다.
- 구간합(점화식) 적용하여 부모노드(현재 index/2 한) index에 현재 값을 더한다
② 질의 값 구하기
- 질의 index 범위를 트리에 맞게 변경
start_index + 2ᵏ -1 ~ end_index + 2ᵏ -1 - 시작/종료 노드에 대해 독립 노드 선택 검증
start_index % 2 == 1인 조건 & end_index % 2 == 0인 조건 - 1~2 과정 반복
반복 도중 start > end 만족시 종료 후 선택된 노드들의 총 합
③ 업데이트
- 이진트리 특성인 index/2로 부모탐색 및 업데이트
세그먼트 트리는 업데이트가 빠르기 때문에 코딩테스트에서 구간합 문제중 데이터 변경 여부로 구간합 or 세그먼트트리 중 하나를 택한다.
'자료구조 알고리즘 코딩테스트 문제풀이 > 알고리즘 - Do it' 카테고리의 다른 글
| [트리] 최소공통조상 LCA 빠르게구하기 (0) | 2024.01.18 |
|---|---|
| [트리] 최소공통조상(LCA) 기본 탐색 (0) | 2024.01.17 |
| [트리] 이진트리(Binary) (0) | 2024.01.16 |
| [트리] Tree 개념 정리 (1) | 2024.01.15 |
| [그래프] 크루스칼-최소신장트리 MST(Minimum Spanning Tree) (0) | 2024.01.14 |